Observabilidad
En el documento anterior deployaste tu aplicación Spring Boot a un VPS con Coolify. Ahora que las apps están corriendo en producción, necesitás saber qué están haciendo realmente—sin tener que agregar print statements y redeployar. Cuando algo se rompe a las 3 de la mañana, necesitás rastrear requests entre servicios, ver logs de errores en contexto y entender cuellos de botella de performance sin adivinar.
Cómo funciona la instrumentación
El proceso se divide en tres pasos lógicos:
-
Recolección de datos (La Aplicación): Modificás la app para incluir código especializado que recolecta varios tipos de datos sobre el estado interno de la app y el entorno del servidor host.
-
Almacenamiento de datos (Los Backends de Telemetría): Los datos recolectados se envían fuera del proceso de la aplicación y van a backends de telemetría correspondientes y optimizados, bases de datos diseñadas específicamente para logs, métricas o traces.
-
Visualización (El Dashboard): Usás una herramienta de visualización poderosa (como Grafana) para extraer los datos almacenados de los backends y presentarlos en dashboards coherentes y legibles.
Los tres pilares de los datos de telemetría
La instrumentación se enfoca en recolectar tres tipos distintos de datos, a menudo referidos como "Los Tres Pilares" de la observabilidad:
| Tipo de Dato | Definición | Backend de Telemetría Común |
|---|---|---|
| Logs | Registros de texto de eventos específicos o estados que ocurren dentro de la aplicación. | Loki |
| Métricas | Puntos de datos numéricos y agregados (ej., uso de CPU, conteos de latencia de requests, consumo de memoria). | Prometheus |
| Traces | El viaje completo de un solo request a medida que fluye a través de las diversas partes de tu sistema. | Tempo |
Grafana actúa como el "único panel de vidrio" que unifica los tres tipos de datos. Es una plataforma de visualización basada en web que se conecta a múltiples backends de telemetría simultáneamente.
Estas son las opciones más comunes en el ecosistema de Grafana, pero no son las únicas. Las alternativas incluyen Elasticsearch para logs, InfluxDB para métricas, y Jaeger para traces.
Visión general de la arquitectura de observabilidad
Así es como las partes móviles se integran entre sí:
El flujo funciona así:
- Las apps de Spring Boot exponen métricas vía Micrometer y envían traces vía OTLP a Tempo
- Promtail scrapea los logs de contenedores Docker y los envía a Loki
- Prometheus scrapea métricas del endpoint
/actuator/prometheusde cada app - Grafana consulta los tres backends para mostrar dashboards unificados
A continuación, un resumen de los archivos nuevos y modificados:
Configuración del repositorio
Micrometer Registry Prometheus
Agregá micrometer-registry-prometheus para exponer métricas en formato Prometheus en /actuator/prometheus
- Java
- Kotlin
- Groovy
implementation 'io.micrometer:micrometer-registry-prometheus:1.17.0-M2'
implementation("io.micrometer:micrometer-registry-prometheus:1.17.0-M2")
implementation 'io.micrometer:micrometer-registry-prometheus:1.17.0-M2'
Configuración de la aplicación
Habilitá los endpoints de observabilidad y configurá dónde enviar los traces.
- Java
- Kotlin
- Groovy
- management.endpoints.web.exposure.include: Expone los endpoints de health, info, prometheus y metrics
- management.tracing.sampling.probability: Configurá en
1.0para tracear el 100% de los requests (reducir en producción) - management.otlp.tracing.endpoint: Envía traces a Tempo vía protocolo OTLP HTTP
- logging.pattern.level: Incrusta el contexto de trace (trace_id, span_id, trace_flags) en cada línea de log
Configuración de la observabilidad
Configuración de Docker Compose
Agregá los servicios del stack de observabilidad a tu docker-compose.yml:
Cada servicio de Spring Boot recibe dos adiciones:
depends_on: Asegura que Tempo inicie antes que las appsnetworks: Se une a la redmonitoringpara que las apps puedan llegar a Tempo
El stack de observabilidad incluye:
- Prometheus: Scrapea métricas de todos los servicios
- Loki: Almacena e indexa datos de logs
- Promtail: Recolecta logs de contenedores Docker y los reenvía a Loki
- Tempo: Recibe y almacena traces distribuidos
- Grafana: Visualiza métricas, logs y traces en dashboards unificados
En algunos proyectos, es común encontrar los servicios de observabilidad
viviendo en un proyecto de Docker Compose completamente separado, o incluso
gestionados por proveedores terceros como
Datadog o Grafana
Cloud. Meter todo en un solo
docker-compose.yml acá mantiene las cosas simples para la documentación y
hace que el setup sea más fácil de seguir.
Loki
Loki es un sistema de agregación de logs horizontalmente escalable, altamente disponible y multi-tenant inspirado en Prometheus.
Dockerfile:
FROM alpine:latest AS builder
RUN mkdir -p /loki/chunks /loki/rules
FROM grafana/loki:3.5.10
COPY /loki /loki
COPY observability/loki-config.yml /etc/loki/local-config.yaml
USER 10001
Usa un build multi-stage para crear directorios con permisos correctos (Loki corre como usuario 10001).
Configuración:
- auth_enabled: false: Deshabilita la autenticación para desarrollo local
- storage.filesystem: Usa almacenamiento de filesystem local (adecuado para configuraciones de un solo nodo)
- retention_period: Mantiene logs por 15 días (360 horas)
- analytics.reporting_enabled: false: Deshabilita el reporte de uso anónimo
Promtail
Promtail es un agente que envía el contenido de logs locales a Loki.
Dockerfile:
FROM grafana/promtail:3.5.10
COPY observability/promtail-config.yml /etc/promtail/config.yml
Configuración:
- docker_sd_configs: Descubre contenedores Docker automáticamente
- relabel_configs: Filtra solo servicios
spring-*y renombra labels - pipeline_stages: Parsea líneas de log para extraer el nivel de log y crear labels indexadas
El patrón regex trace_id=\S+ span_id=\S+ trace_flags=\S+ (?P<type>\w+) \S+ --- extrae el nivel de log de tu formato de log de Spring Boot, habilitando el filtrado por tipo de log (INFO, ERROR, DEBUG, etc.) en Grafana.
Tempo
Tempo es un backend de tracing distribuido de alto volumen con dependencias mínimas.
Dockerfile:
FROM alpine:latest AS builder
RUN mkdir -p /tmp/tempo/blocks /tmp/tempo/wal /tmp/tempo/generator/wal && \
chown -R 10001:10001 /tmp/tempo
FROM grafana/tempo:2.10.0
COPY /tmp/tempo /tmp/tempo
COPY observability/tempo.yml /etc/tempo/tempo.yml
CMD ["-config.file=/etc/tempo/tempo.yml"]
Crea directorios requeridos con ownership apropiado antes de copiar el binario de Tempo.
Configuración:
- distributor.receivers.otlp: Acepta traces vía OTLP en los puertos 4317 (gRPC) y 4318 (HTTP)
- storage.trace.backend: local: Usa filesystem local para almacenamiento de traces
- metrics_generator: Habilita la generación de service graph y span metrics
- usage_report.reporting_enabled: false: Deshabilita el reporte de telemetría
Prometheus
Prometheus es un toolkit de monitoreo y alerting de sistemas que recolecta y almacena sus métricas como datos de series temporales.
Dockerfile:
FROM prom/prometheus:v3.9.1
COPY observability/prometheus.yml /etc/prometheus/prometheus.yml
Configuración:
- scrape_interval: Recolecta métricas cada 60 segundos
- scrape_configs: Define tres jobs para scrapear métricas de cada servicio de Spring Boot
- metrics_path: Apunta a
/actuator/prometheusdonde Micrometer expone las métricas
Grafana
Grafana provee visualización y análisis para tus datos de observabilidad.
Dockerfile:
FROM grafana/grafana:11.6.11
COPY observability/grafana/datasources /etc/grafana/provisioning/datasources
COPY observability/grafana/dashboards/dashboards.yml /etc/grafana/provisioning/dashboards/dashboards.yml
COPY observability/grafana/dashboards/*.json /var/lib/grafana/dashboards/
Copia la configuración de provisioning de datasources y dashboards en tiempo de build.
Configuración de Datasources:
Configura tres datasources:
- Prometheus: Para métricas, marcado como default
- Loki: Para logs, con extracción de trace ID para correlación
- Tempo: Para traces, con links de vuelta a logs de Loki
Las configuraciones exemplarTraceIdDestinations y derivedFields habilitan la correlación de trace a log. Cuando ves un pico de métrica, podés clickear para ver el trace; cuando ves logs, podés clickear el trace ID para ver el trace distribuido completo.
Configuración de Dashboards:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
updateIntervalSeconds: 10
allowUiUpdates: false
options:
path: /var/lib/grafana/dashboards
foldersFromFilesStructure: false
Habilita la carga automática de dashboards desde /var/lib/grafana/dashboards.
El repositorio incluye dos dashboards pre-configurados adaptados de la comunidad de Grafana:
JVM Micrometer (
dashboard 4701
): Métricas de JVM incluyendo memoria, threads, GC y carga de clases
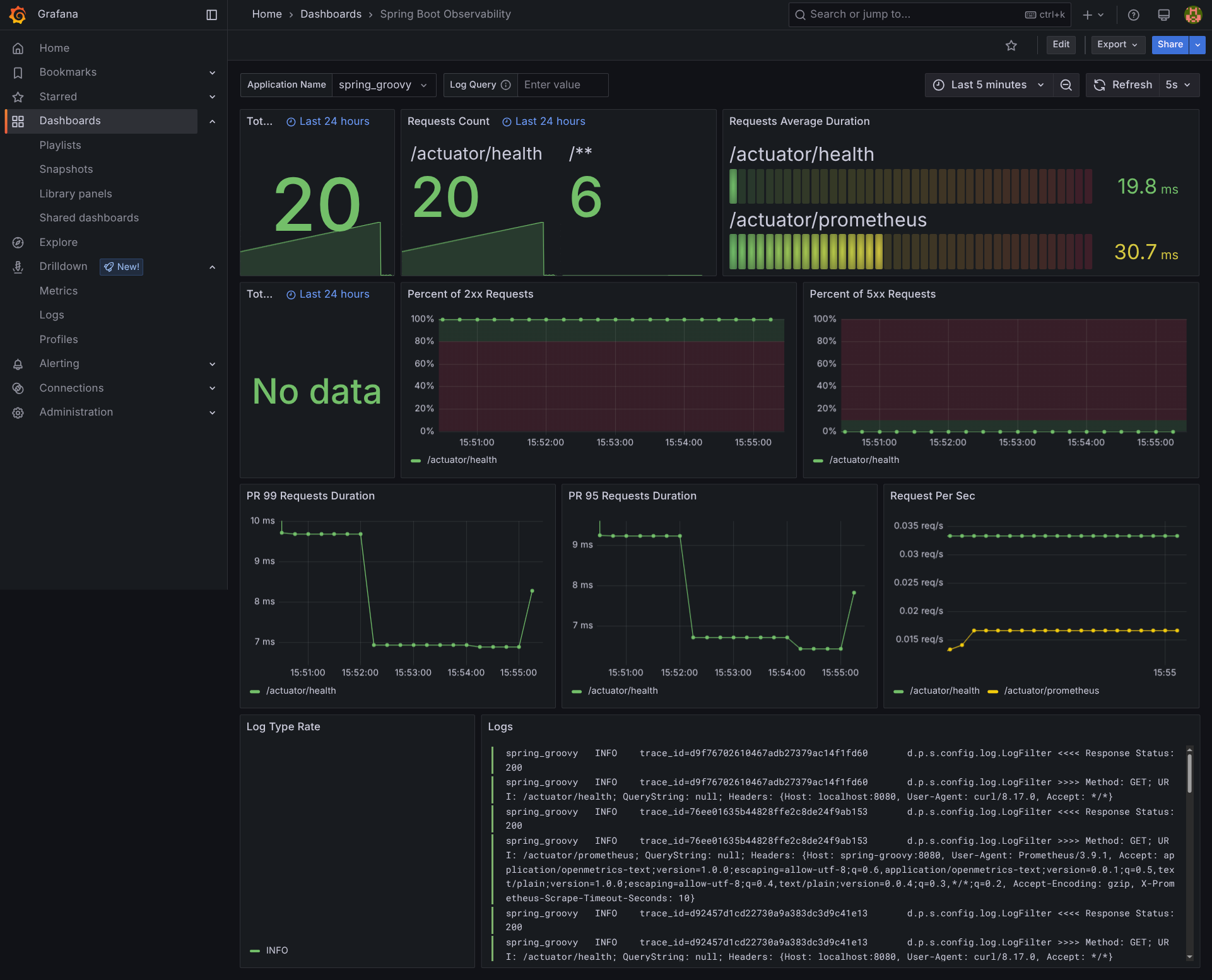
Spring Boot Observability (
dashboard 17175
): Métricas a nivel de aplicación con tasas de requests HTTP, tiempos de respuesta y tasas de error
Estos se omiten del patch debido a su tamaño (miles de líneas de JSON), pero
podés encontrarlos en el repositorio en
observability/grafana/dashboards/.
Deploy a producción con Coolify
Cuando deployás a Coolify, la plataforma detecta automáticamente los nuevos servicios definidos en tu docker-compose.yml y los inicia junto con tus aplicaciones de Spring Boot. No necesitás configurar manualmente el stack de monitoreo.
El único paso adicional es asignar un dominio a Grafana para que puedas acceder a los dashboards:
- En Coolify, encontrá el servicio de Grafana en tu proyecto
- Clickeá en él y configurá un dominio (ej.,
grafana.tudominio.com) - Coolify se encargará de los certificados SSL y el routing
Grafana espera que las variables de entorno
GF_SECURITY_ADMIN_USER y GF_SECURITY_ADMIN_PASSWORD
estén configuradas. Asegurate de definirlas en la configuración del servicio
de Coolify antes de iniciar el stack.
Acceso a Grafana
Una vez logueado, los dashboards pre-configurados están disponibles en:
https://grafana-domain-you-have-set-in-coolify/dashboards
Vas a encontrar:
- JVM Micrometer: Internals de JVM (pools de memoria, garbage collection, threads)
- Spring Boot Observability: Métricas HTTP, tiempos de respuesta, tasas de error
Con el stack de observabilidad en marcha, ahora tenés visibilidad completa de tus aplicaciones: métricas en Prometheus, traces en Tempo, y logs en Loki, todo unificado a través de dashboards de Grafana. Cuando algo se rompe en producción, podés rastrear un request end-to-end, saltar de un pico en una métrica a los logs relevantes, y encontrar la causa raíz sin adivinar.